Architecture of Low-latency Quoting Stream System for Quantitative Trading
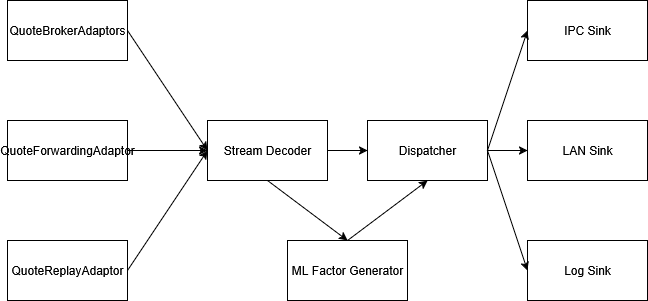
High-Level Architecture
The system follows a modular yet monolithic design moving from data ingestion through decoding, calculation, and distribution.
Data Structure
L1 Market Data
While L1 Market Data is the standard for retail platforms and low-frequency strategies; it lacks the granularity required for HFT (High-Frequency Trading).
Typical L1 Payload:
1 | struct L1_Tick { |
L2 Market Data
Level 2 Market Data represents the Depth of Book. It is either Market by Order (MBO) or Market by Price (MBP).
In the Shanghai and Shenzhen Stock Exchanges (SSE/SZSE), the Level 2 data is MBO feed. Instead of receiving aggregated price levels, the exchange broadcasts every individual limit order and transaction. Also 20-level deep of the order book is intergrated into the snapshot.
The L2 Market Data types are: Snapshot, Orderbook, Order, and Transaction. Snapshots and orderbooks are typically broadcast at fixed intervals, while orders and transactions are streamed tick-by-tick.
Typical L2 payload:
1 | constexpr int MAX_SYMBOL_LEN = 16; |
ML Factors
Matrix of floating values and ternary states.
Components
Quotes Adaptors
The ingestion layer abstracts the complexity of upstream connectivity. The adaptor is loaded at the runtime as a dynamic libarary.
QuoteBrokerAdaptors
The most protocol-intensive component. Upstream sources range from the exchanges’ raw UDP broadcast to TCP-based broker’s APIs. It manages packet sequencing, handling out-of-order, duplicate, or missing.
QuoteForwardingAdaptor
For internal topology, it ingests aggregated or filtered feeds forwarded from other internal network nodes.
QuoteReplayAdaptor
Streams historical data from the DB or a raw PCAP file for backtesting and research.
Stream Decoder & Machine Learning Factor Generator
The Stream Decoder translates raw, fragmented exchange/broker protocols into our internal data structures.
ML Factor Generator is intentional like a black box to the engineering team. The core mathematics remain proprietary to the quantitative team. The generator exposes decoupled interfaces to the quants to inject their models as shared libraries at runtime. The pipeline’s memory layout and IPC routing are specifically optimized to handle two distinct signal types:
Regression Outputs: High-precision floating-point values. These typically represent continuous metrics, such as slight deviations from the top-of-book price or real-time fair-value calculations.
Classification Outputs: Discrete ternary states (-1, 0, 1). These serve as the directional triggers.
Dispatcher & Sinks
IPC sink:
The critical path for execution, utilizing a Single-Producer, Multiple-Consumer (1-Writer, M-Readers) lock-free shared memory architecture.
The SHM segment begins with a control header includes the Provider PID and Launch Timestamp. During startup, the Feed Handler performs a mandatory check on the stored PID & launch time. If an active process is detected, the new instance aborts to prevent dual-writer memory corruption. The launch timestamp allows downstream readers to detect provider restarts, signaling them to clear stale state and re-synchronize.
LAN sink:
Handles external distribution. It routes data over the network to other colocation facilities
Log sink:
Asynchronously persists the stream into binary files for post-trade database ingestion.
Further Questions:
The quoting system is a part of the latency arms race. It is unlikely any competitive HFT system will be open sourced.
- How can we further reduce latency?
Beyond software optimization, we look at Kernel Bypass (using Solarflare Onload or DPDK) to move networking into user-space, avoiding the overhead of the Linux kernel stack. Additionally, CPU Pinning and isolating cores via isolcpus prevents the OS scheduler from interrupting the critical path. For extreme-low-latency requirements, such as HFT arbitrage, the entire system can be offloaded to FPGA hardware.
- Why Shared Memory, and how is data structured within it?
Shared Memory (SHM) allows multiple processes to access the same physical RAM, eliminating the copy-overhead of local sockets and the expensive context switching between kernel and user space. We structure this as a Lock-Free Single-Producer, Multiple-Consumer (SPMC) ring buffer using Atomic Sequence Numbers.
Architecture of Low-latency Quoting Stream System for Quantitative Trading